Procedures of a Compiler
LA 词法分析是源代码在编译器中遇到的第一关
Source Code
↓
[Scanner] → Tokens
↓
[Parser] → Syntax Tree
↓
[Semantics Analyzer] → Annotated Tree
↓
[Optimizer] → Intermediate Code
↓
[Code Generator] → Target Code
- 输入:source code
- 输出:tokens (token =
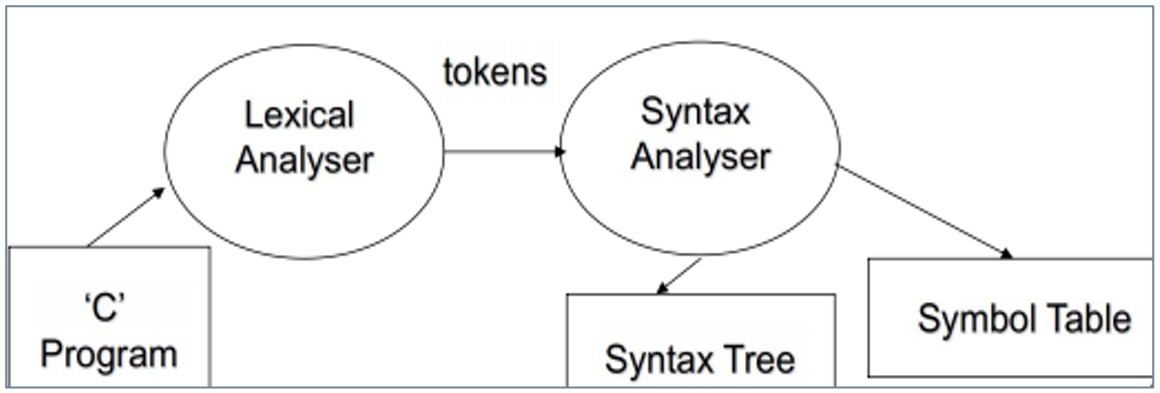
LA / Scanner Functions
词法分析器功能:
- Task:从左到右读取源代码,生成 token
- Input/Output:源代码字符串 → token 序列
- 别称:Scanner(扫描器)
- 核心作用:
- "purify" 输入:去除注释、空白等无关信息
- identify and classify:识别并分类语言成分
The Categories of Tokens
- Reserved words / keywords: the symbols of the language
- 关键字,语言固定的几个符号
- identifiers
- 标识符,用户自己定义的名字,函数名,变量名
- Literal constants
- 常量,字符串,字符,整数
Whitespace and comments, all of which are to be ignored by the syntax analysis phase
词法阶段会处理 空格和注释,会在语法分析阶段被忽视掉
Why a Separate LA Phase?
- It is easier and clearer to separate the input processing into two phases.
- Tokens can be described by a regular grammar, so lexical analysis is efficient.
- All input handling is concentrated in one phase, so processing can be more efficient.
为什么需要单独的词法分析阶段?
A separate lexical analysis phase makes the compiler design easier, clearer, and more efficient. It removes whitespace and comments, converts source code into tokens, and handles input uniformly. Since tokens can usually be described by regular grammar, the lexical analyser can be implemented efficiently using finite-state techniques. It also improves modularity, because different lexical analysers can work with the same syntax analyser.
因为这样可以让编译器设计更清晰、更高效。词法分析先把源代码转换成 token,并去掉空格、注释等无用信息。由于 token 通常可以用正规文法来描述,所以词法分析器可以高效实现。同时,这种分层设计也增强了模块化,不同的词法分析器还可以复用同一个语法分析器
Design of a Simple LA
Two Stages:
- Independent pass scanner:独立预处理,输出 token 流
- Subprogram of parser:作为
getword()被语法分析器调用
Recognizer
- FSM which recognizes words
- 用 FSM 判断是 identifiers, Literal constants, keywords
Translator
- According to the result of FSM
- Completes the translation to token strings
- 将识别的结果输出为 token

Source Code → FSM(识别) → Translator(转换) → Token
String Literals(字符串字面量)
- 由双引号
"界定:text := "the result is"; - 引号内可含任意字符(包括空格、关键字)
- 特殊字符需 escape:
"He said \\"Hello\\", and smiled."以及 \t \b \n
Numeric Literals(数值字面量)
- 支持十进制、十六进制(如
0xFF)、科学计数法(43.3e-12) - 仍可用 regular grammar 描述
Identifiers(标识符)
- 传统规则:
[a-zA-Z][a-zA-Z0-9]* - 部分语言支持
_(如 Java),但通常不作首字符 - $letter (letter | digit)*$
Reserved Words(关键字)
- 预定义集合:
if,for,while,begin,end... - 识别流程:
- 先按标识符规则读取字符串
- 查 keyword table
- 命中 → 返回对应 keyword token;未命中 → 返回 identifier token